プログラムと解説をちょろっと入れた。IMKLの並列処理についてはベンチマークテストの結果を挿入予定。
う~む,疎行列の説明がきつくなってきたなぁ・・・。うまく入るかな?
[進捗報告] SGEMM, DGEMM計算完了
しかしまぁ,GTX780のDGEMMって遅いんだなぁ・・・つーかK20が速いというべきか。こちらのGTX980の結果を見ると更に倍精度は遅いようだし,買うのを躊躇しちゃうレベル。
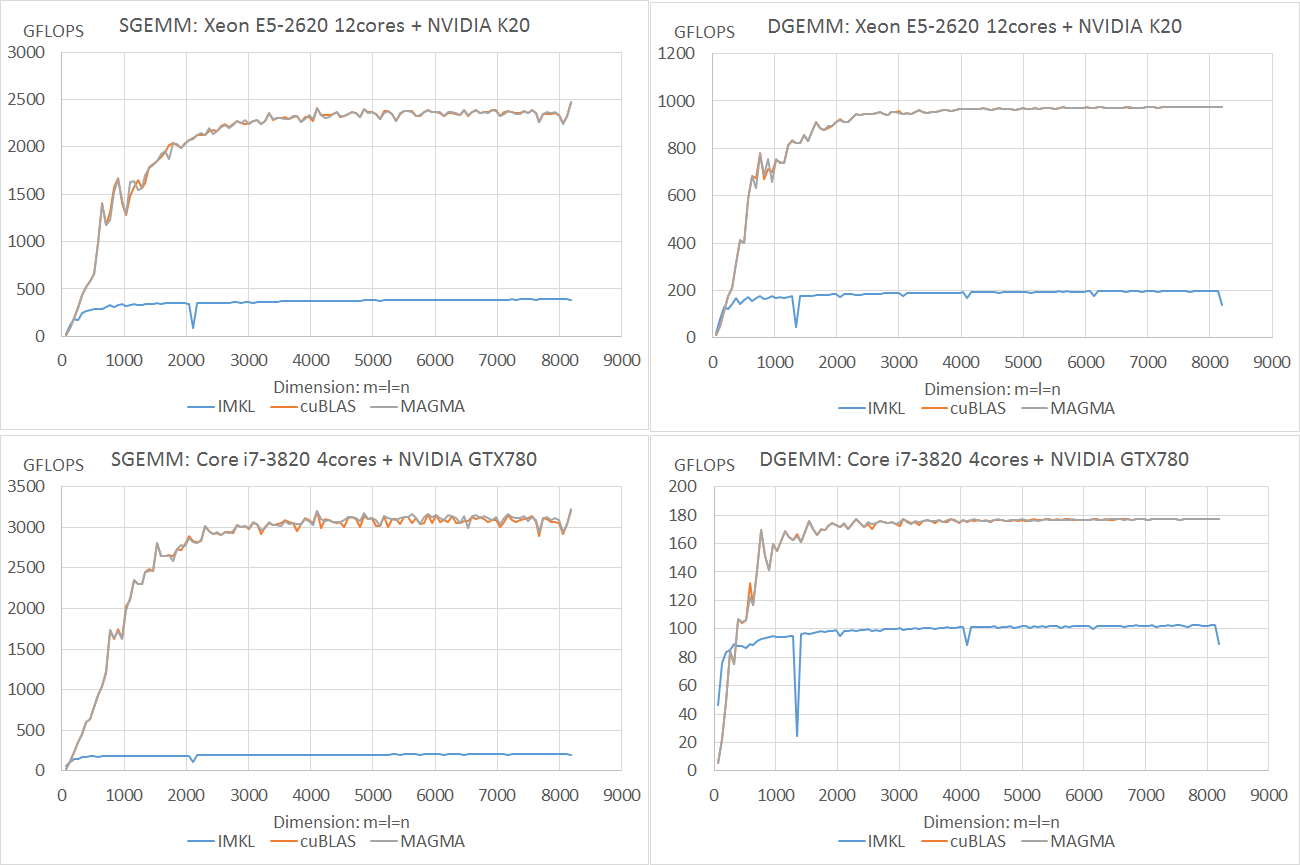
ちなみにMAGMA 1.6.0になって[S,D]GEMMの速度はcuBLASと遜色なくなっておりました。1.6.1とCUDA 7.0との組み合わせは・・・さてどうしようかしらん?
解説は次週に回してガンガン説明を突っ込んでいこう。
[進捗報告] 倍精度行列積ベンチマーク開始
CentOSのバイナリATLASを使うとHT分もCPUをカウントしてしまうらしく,4 coresなのに8 threads使っている模様。とりあえずCore i7 3820+GTX780だとDGEMMで
Ref.BLAS < ATLAS < IMKL < cuBLAS == MAGMA 3.2(GFLOPS) < 20 < 101 < 176 == 176 で,Xeon E5 2620x2 + Tesla K20だと Ref.BLAS < ATLAS < IMKL < cuBLAS == MAGMA 2.5(GFLOPS) < 20? < 196 < 974 == 974 ってとこ。単精度もやっておかないとなぁ。
[進捗報告] OpenMP並列化直接法プログラム制作
ちみっと本文に挿入した図も修正。さて間を埋める文章とデータを作らないと~。
[進捗報告] 直接法の並列化・図挿入
とりあえず並列LU分解と並列前進・後退代入の解説図を挿入。OpenCLも初体験。書かないけど,一応使っておかないと触れることもできませんからな。